AWS: SageMaker Service
Amazon AI/ML Stack
Application Services – These are domain-based
services which allow us to very quickly generate predictions with pre-trained
models using simple API calls.
Platform
Services – Unlike Application services, platform services allow us to build
our customized Machine Learning and AI solutions through optimized and scalable
options. The SageMaker service that we will discuss in this article, falls in
this tier.
Frameworks and Hardware – The tiers mentioned
above run on top of the frameworks and hardware tier. This layer provides a
wide range of optimized deep learning tools like TensorFlow, Keras, Pytorch and
Apache MXNet. Options of compute options (GPU, CPU) are also available.
Amazon SageMaker
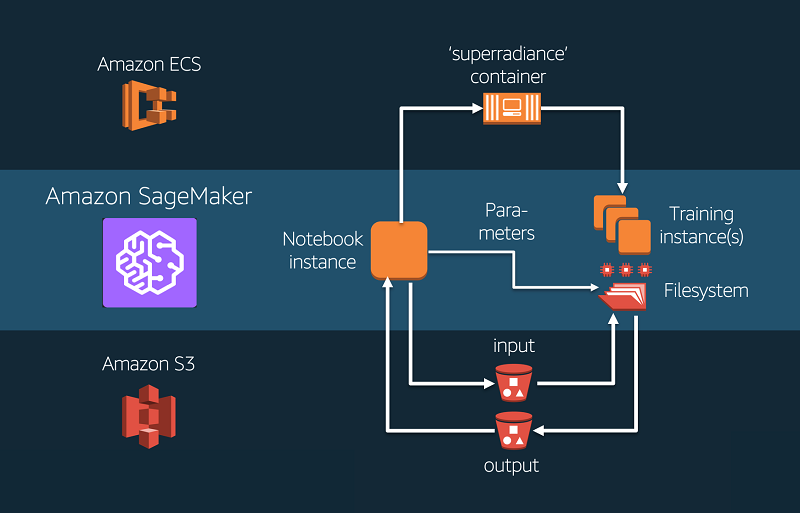
Now that we know where Amazon’s SageMaker Service falls, lets delve a bit deeper into it.
A generic Machine Learning Pipeline has the following
primary modules:
· Data Processing
· Data Analysis
· Feature Engineering
· Model Training and Tuning
· Prediction Generation
· Deployment to End User
SageMaker combines these modules and works with three major
components:
- Build – Involves data extraction from S3, Docker or any other storage option used. Processing and feature engineering follow.
- Train – This component combines model tuning and model training
- Deploy – This component allows us to deploy the predictions and save them to the preferred storage location.
These components are independent of each other and can be
used separately or even in required combinations.
The management of SageMaker components is extremely easy
through Amazon SageMaker Console which has a very clean layout, making options
for the different components easily accessible and configurable.
BUILD
The build phase initiates the first interaction of Data with
the Pipeline. The easiest way to do this is to generate SageMaker’s Notebook Instances. This not only
enables the integration of the required code but also facilitates clear
documentation and visualization.
The other options available for code integration is Spark
SDK which enables integration of Spark pipeline through AWS’s Elastic Map
Reduce or EMR service.
TRAIN
Setting up training module in SageMaker is extremely easy
and feasible. The primary attractions of the training component in SageMaker
are as follows:
- Minimal Setup requirements – on creating a simple training job, SageMaker takes care of the hardware requirements and backend jobs like fetching storage and instances.
- Dataset Management – SageMaker takes care of streaming data and also helps manage distributed computing facilities which can help increase the speed of training.
- Containerization – All models in SageMaker, whether it is an in-built model like XGBoost or K-Means Cluster, or a custom model integrated by user, are stored in Docker containers. SageMaker efficiently manages and integrates the containers without any external aid from users.
DEPLOY
There are several deployment options in SageMaker. With
SageMaker’s UI, it is a one-step deployment process, providing high reliability
with respect to quality, scalability and high throughput facilities.
Several models can be deployed using the same end-point (the
point of deployment) so that the model can go through A/B testing which is supported
by SageMaker.
One major advantage of the deployment facility is that
SageMaker allows upgrades, updates and other modifications with zero downtime,
owing to blue-green deployment (when two similar production environments are
live such that if one goes down, the other one keeps the server up and running).
Batch predictions, which are often required in production,
can also be carried out using sageMaker with specific instances which would
stream data in from and out f S3 and distribute the tasks among GPU or CPU
instances (as per the configuration).
ADDITIONAL FUNCTIONAL LAYERS
ALGORITHMS
|
FRAMEWORKS
|
DOCKER
|
TUNING
|
SageMaker has some in-built algorithms which have been optimized
specifically for the AWS platform. The optimizations are tailored to work efficiently
with distributed training and high-end processors like GPUs.
|
SageMaker allows to sample data and work on that slice of data using your
chose framework scripts on a single notebook instance. Once done, this can be
scaled to the full dataset using a bunch of GPU instances.
|
Docker helps to implement frameworks and models that are not
supported by SageMaker. Thus, integration with Docker increases the scope of
SageMaker manifold.
|
Automatic model tuning is a facility provided by SageMaker to
optimize model parameters to get the best fit. It uses a meta-model built on
top of the model in question, to predict which combination can plausibly give
the best fit.
|
With this, we have come to the end of Amazon SageMaker basic
concepts. Watch this section for a DEMO on how to get started with
SageMaker, which will be published soon.
For any questions or suggestions, you can drop a mail at ghoshsamadrita3@gmail.com
Or DM me on LinkedIn https://www.linkedin.com/in/samadritaghosh/
Looking forward to connect with you and your ideas!










Comments
Post a Comment